
Note - I am a beginner in C++, but I've been self-learning it for the last few months. If you are a C++ pro and notice something absolutely egregious in my code, please tell me. Really. Also - I have since updated the code for this but maybe I can talk more about that in part 2.
Fly.io Distributed Challenges
The past few days I've been working through some fun distributed systems challenges from fly.io. The challenges utilize a program called Maelstrom which allows you to implement nodes in a distributed system and have those nodes be tested under various constraintss. Maelstrom itself is built upon Jepsen, which is a clojure library for testing real distributed systems and validating certain claims about those systems. For example if a system claims to implement linearizability, Jepsen might be able to find bugs that disprove that claim by testing the application while simulating real issues such as clock skew or network partitions. You can read some of their analyses from testing various platforms including ScyllaDB, Redis, Etcd and many others.
Although the challenges can be implemented in any language, most of the documentation (at the time of this writing) is written for go. Although there is also demo code in JavaScript and Java, I have been attempting to teach myself C++ lately and thought this might be a wonderful opportunity to learn by doing. I've also been teaching myself some of the deeper concepts in the world of distributed computing (I am almost done reading Designing Data-Intensive Applications). So this has been a dual challenge for me, one to learn an absolute unit of a programming language (C++, and myself coming from the Python/PHP/JS world), and the other understand better some distributed systems concepts. As a self-taught developer this hasn't been that easy, but with the help of an awful lot of youtube videos (including Kleppmann's lectures on distributed systems), articles, books, and a healthy dose of chatGPT, I think I have achieved a decent understanding.
Gossip Protocol
The broadcast challenge itself is basically what amounts to implementing gossip protocol, which is a way to diseminate a message across the entire network of nodes by each node passing along every message it receives to some subset of nodes that it considers as its neighbors. You could just pass every message to every other node in the network, but this would be inefficient - the algorithmic complexity turns quadratic O(n^2) for every message passed in the network. So instead we can opt to pass messages to our neighbors. The broadcast challenge conveniently gives us a topology of the network, including some neighbors that we can use, though I found that using their neighbors didn't work out when the challenge encroaches upon our neat system with network partitions. In the end, I had to set the topology to that of a spanning tree using the --topology tree3 maelstrom command line option.
Here are some diagrams that hopefully get the point across. First a message arrives at some node in the system, then that node broadcasts the message to its neighbors, and those neighbors pass the message to their neighbors, etc. This continues until the message eventually reaches all nodes in the system.
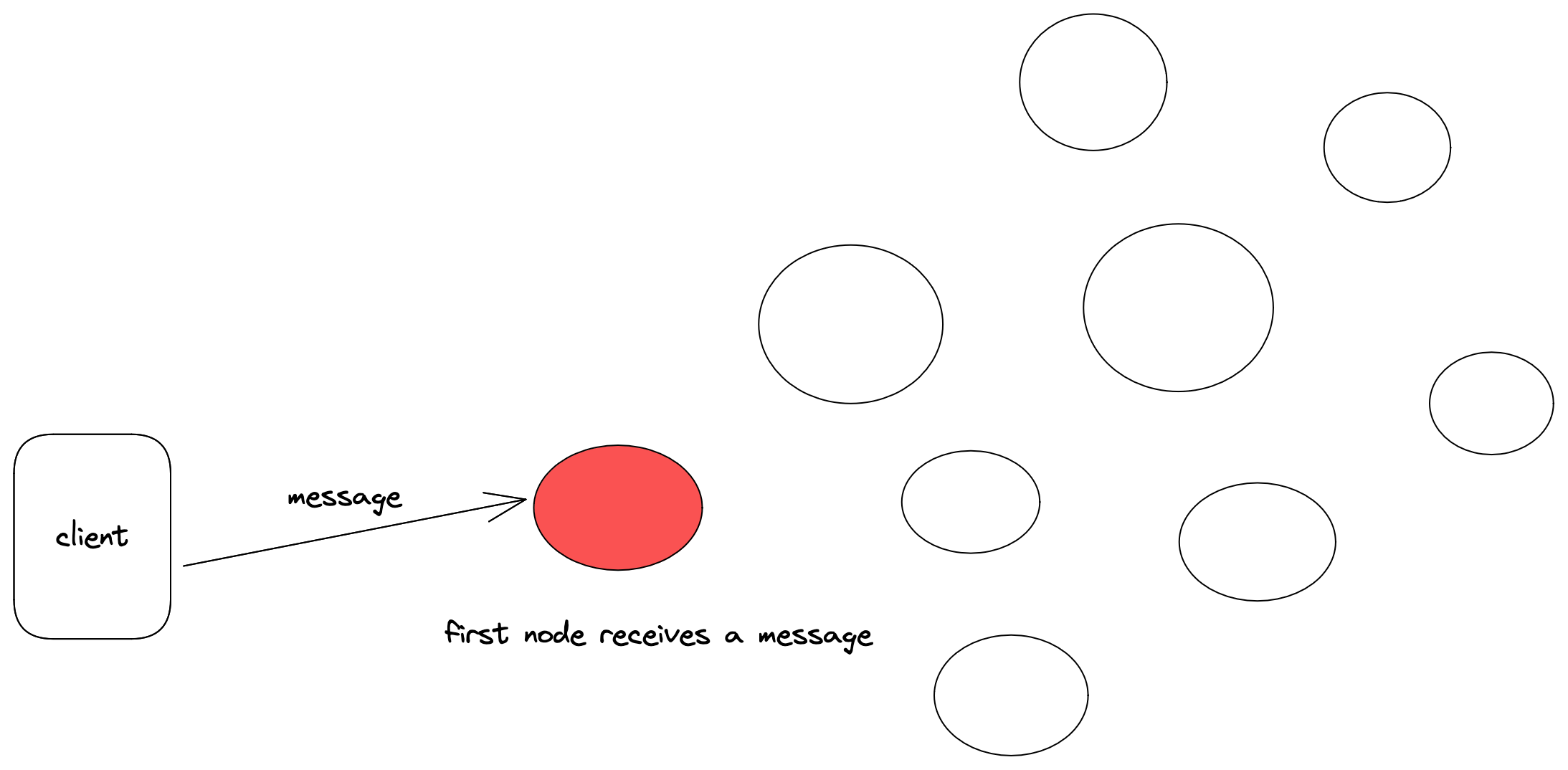
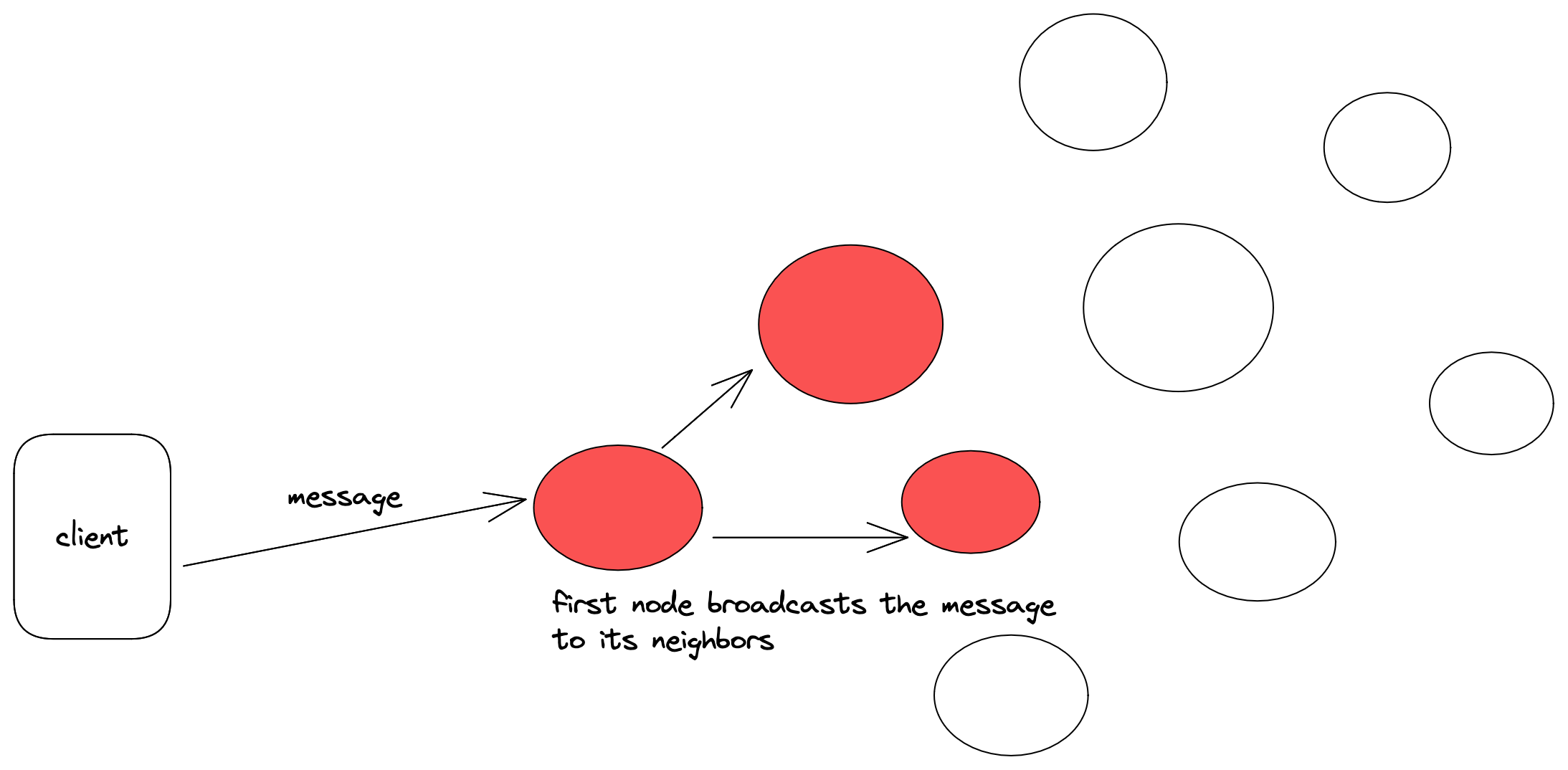
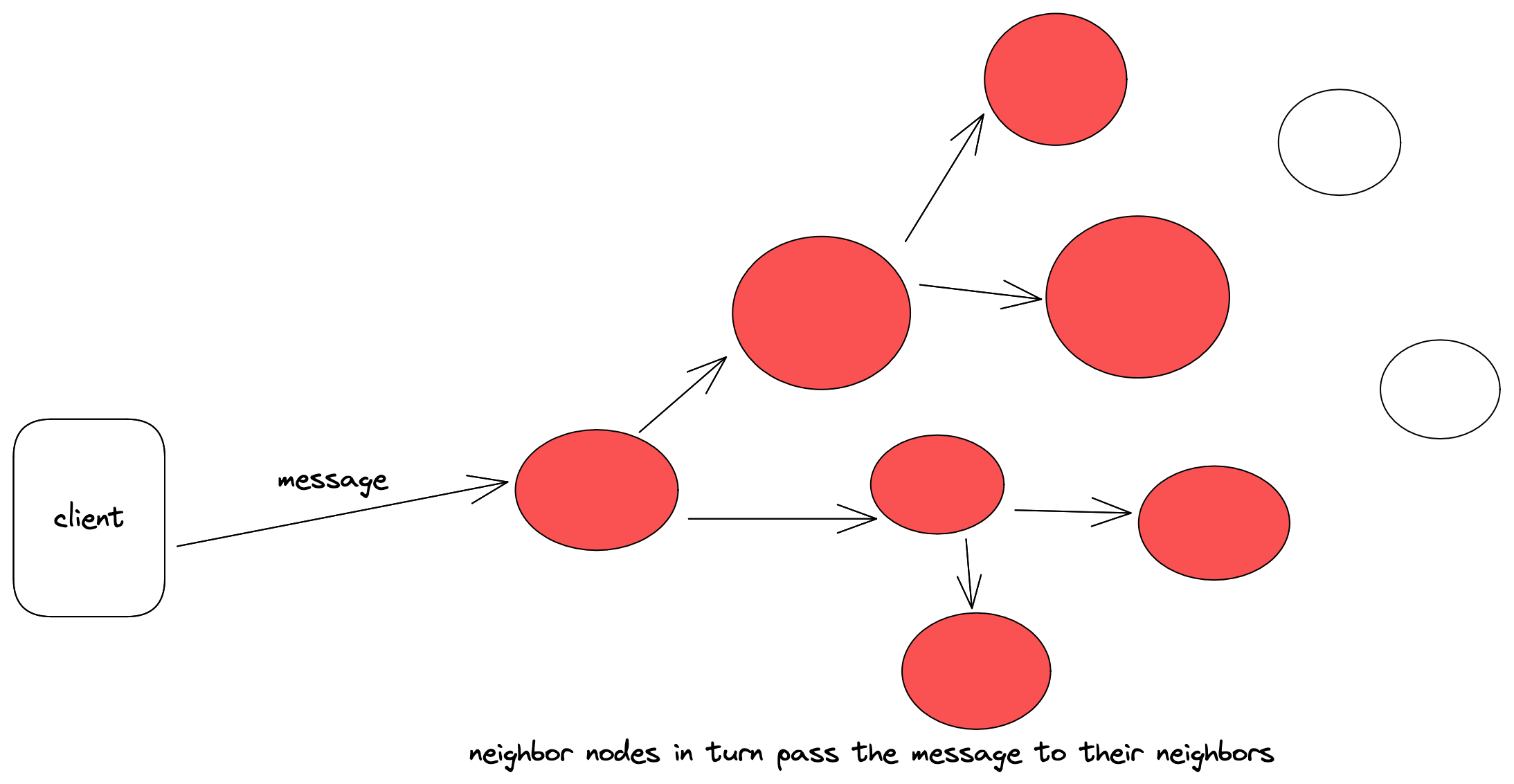
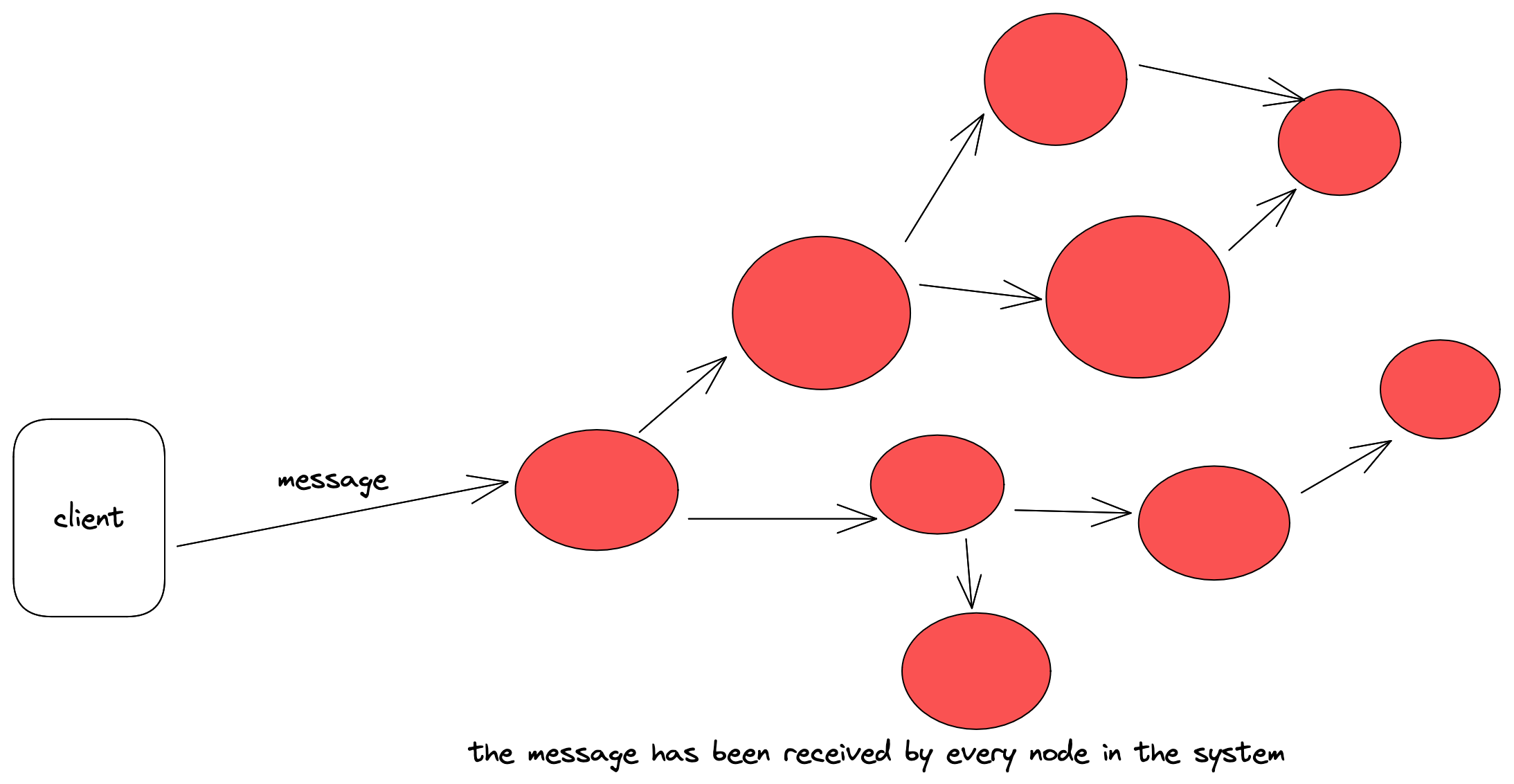
Though this was easy enough to implement, I ran into some trouble getting my system to pass the efficiency portion of the challenge. The first iteration of my solution simply had each node gossip to its neighbors upon receiving any broadcast message. This was inefficient for to two reasons. The first is that every single message was being sent by itself, so once a node received a message, it would send only that one message to all of its neighbors. This lead to sending too many messages when really they could be batched. The second problem was that each broadcast message sent to each node was also waiting on the for loop to send the gossip message to each neighbor. The send event here simply sent and waited for a response, which in the event of a network partition obviously slowed things to a crawl. The original method went something like this:
node.on("broadcast", [&node](const json& req) {
// add the new message to my own set of messages
json req_data = json::parse(req["body"]["message"]);
int msg = req_data.at("body").at("message").get<int>();
node.messages.insert(msg);
// gossip this message to all my neighbors
for (const auto& peer : node.peers) {
if (peer != req_data.at("src").get<string>()) {
node.send(peer, {{"type", "gossip"},
{"message", msg},
{"msg_id", node.newMsgId()}});
}
}
})To get around this, instead of sending each message on every broadcast, I maintain an unordered map to keep track of messages that I know my neighbors have seen (a map with keys of node_id and values of a set of messages). This way, when I gossip to my neighbors, I simply find the difference between the sets and send that. Additionally, I spawn a separate thread upon initialization of the node, that periodically (every 300ms) sends a 'gossip' event to an asynchronous message queue. The main loop of the node then switches back and forth between the reading standard input (how the maelstrom network communicates) and processing messages from the queue. So now when a node receives a broadcast event, it simply inserts the new message into my two internal variables (my current node's messages and the map) and returns a 'broadcast_ok' message to the sender. The updated broadcast handler looks like this:
node.on("broadcast", [&node](const json& req) {
int msg = req["body"]["message"];
node.peerMessages[req["src"]].insert(msg);
node.messages.insert(msg);
node.reply(req, {{"type", "broadcast_ok"}});
});The gossip protocol implemented this way is transformed from a "best effort" broadcast to a "reliable" broadcast. This is becauset if a given node is not available due to, for example, a network partition, then that is okay because we will still send all of the messages they are missing in the next round of gossip. The messages are also idempotent because we use a set to only append the messages that they are missing. We could in theory have sent all the messages every time and still kept this idempotency (since each node's internal messages are themselves a set), but we don't want to congest network traffic unnecessarily. This also means that our messages are now implemented in an exactly once manner, due to the combination of retrying and idempotency. Of course, this is pretty easy since our messages are just integers in this scenario, so the more difficult part of this idea would be implementing idempotent updates to our nodes (or state machines, if you'd like to call them that) such that they all converge on the same state. If our updates are commutative, i.e., the order in which we apply them doesn't matter, then clearly the order in which messages are causally related doesn't really matter. That is the case here, where if we receive a message it is simply an integer to add to our set, and is naturally ordered in the standard set container by C++, which is implemented as a red-black tree.
By the way, I initially got this idea from Jon Gjengset by watching his implementation of these very same challenges in Rust. You can find his code here. His nodes are a bit more formally implemented as state machines. I should also mention that I was linked to that video in the SysDesign meetup slack channel, which is run by Dima Korolev.
Vector Clocks
The above implementation is sufficient to pass the fly.io broadcast challenge. However, just to make it a little more interesting, I thought it'd be fun to maintain some order of our messages. Right now when a maelstrom client sends a read request they are not really guaranteed any ordering. They are, in the sense that the standard set (again, a red-black tree) is always going to return the integers in order, but that's more happenstance due to the nature of this primitive challenge. I though hacking the jepsen code a bit to turn the expected integer messages into random strings would work nicely for a proof of concept. This way, the order in which the messages came in would not reflect at all the sorted order of the strings. In other words, string "abc" might have an ordinally smaller value than "xyz", but the latter might have been introduced later in time and in fact may have caused the former to come about in the first place.
Here is some of the 'hacked' portion of the jepson maelstrom code, where I replace the map function that populates broadcast value as an integer with a "random-string" function:
(defn random-string [n]
(let [chars "abcdefghijklmnopqrstuvwxyz0123456789"]
(apply str (repeatedly n #(rand-nth chars)))))
(defn workload
"Constructs a workload for a broadcast protocol, given options from the CLI
test constructor:
{:net A Maelstrom network}"
[opts]
{:client (client (:net opts))
:generator (gen/mix [(->> (range)
(map (fn [x] {:f :broadcast, :value (random-string 4)})))
(repeat {:f :read})])
:final-generator (gen/each-thread {:f :read, :final? true})
:checker (checker)})To further exemplify this, imagine our application is a popular streaming site with a chat function. There are users from all over the world who are sending messages to comment on what is happening live on the stream. So the stream could be a baseball game, and everyone is chatting about the game in real time. If user cubs_lady93 comments a question, such as "Who is everyone's favorite player?", we would expect that question to arrive before the answers do. So a reasonable order of chats might be:
- cubs_lady92: Who is everyone's favorite player?
- crash_override: Derek Jeter!
- giants_fan: willie mays!
That's all well and good and I'm sure you could guess what an unreasonable order of messages might be:
- crash_override: Derek Jeter!
- giants_fan: willie mays!
- cubs_lady92: Who is everyone's favorite player?
So while our chat app is not mission critical, you can see how we might be interested in causal consistency, in that there are chat messages that are causally related to others. This is like physics almost, one force or event (like the origin of the universe, for example) might literally have caused another, so that causing force must have come about first. On the other hand, if two forces or events don't have any impact on each other at all, then they are concurrent. If they are concurrent than we don't really need to put any definitive order to them. We could put them in some total order, but we don't have to, and in the case of our chat example we don't really need to. If two users posed two different questions at the same time, the order of those questions wouldn't make much of a difference.
- cubs_lady92: Who is everyone's favorite player?
- MetsFanatic: Who do you think will win?
These two questions are causally unrelated to each other, so for an end user it makes no difference:
- MetsFanatic: Who do you think will win?
- cubs_lady92: Who is everyone's favorite player?
Back to our C++ code, we can update the nodes with broadcast middleware that will hold messages we receive in a buffer, and only "deliver" them to our node when we know what order we should put them in.
In order to achieve causal consistency we can determine the order of events using vector clocks. In addition to our logical clocks, it is not enough to send them only within our cluster, we need some help from the client side as well, at least in our example. This is because currently the maelstrom clients are reading all messages from any given node (or at least all the messages that that node has had delivered to it). Given that a read can cause a client to make a write in our imaginary chat system (for example, maybe a response to an insult about a user's favorite baseball team), it makes sense that the client itself needs to hold the logical clock and send it with every write. This is how we can determine causal order across the entire cluster. Alternatively we can also simply maintain a "sticked" connection between clients and cluster node so that every client read and write request goes to the same node.
Here is a simple implementation we can use in our imaginary app. We assign a vector clock as a member of our node class, and within the vector clock itself we can use an actual vector wherein each index of the vector can represent each node in our cluster. The values of each index then represents the number of messages that have been "delivered" to that node at that point in time, which will of course start with zero. Each node in our cluster will have a vector clock and so with this we will be able to determine causally related messages. For example, let's say that we have a three node cluster. If node 0 receives an event with the vector clock of (0, 1, 1), and then another event with the vector clock of (0, 1, 2), it will know that the first event causally precedes the second. Similarly, if node 0 receives an event with the vector clock (0, 0, 1), and then another event with the vector clock (1, 0, 0), it will know that the two events are not causally related, i.e., they are concurrent events.
Here is a basic vector clock in C++. We can set a private variable of a map of string, integer pairs. We could simplify this to be integer pairs as our actual node names in this system are "n0", "n1", etc. but we can keep it this way for now.
std::map<std::string, int> vclock;Now we can implement some methods to compare our vectors (and thus determine causal order).
bool VectorClock::isConcurrent(const VectorClock &other) const {
bool hasGreater = false;
bool hasLesser = false;
for (const auto &entry : vclock) {
const std::string &process = entry.first;
int our_time = entry.second;
int other_time = other.getTime(process);
if (our_time > other_time) {
hasGreater = true;
} else if (our_time < other_time) {
hasLesser = true;
}
if (hasGreater && hasLesser) {
return true;
}
}
return false;
}We can write similar functions for less than and greater than.
bool VectorClock::isLessThan(const VectorClock &other) const {
bool hasLesser = false;
for (const auto &entry : vclock) {
const std::string &process = entry.first;
int our_time = entry.second;
int other_time = other.getTime(process);
if (our_time > other_time) {
return false;
} else if (our_time < other_time) {
hasLesser = true;
}
}
return hasLesser;
}
bool VectorClock::isGreaterThan(const VectorClock &other) const {
bool hasGreater = false;
for (const auto &entry : vclock) {
const std::string &process = entry.first;
int our_time = entry.second;
int other_time = other.getTime(process);
if (our_time < other_time) {
return false;
} else if (our_time > other_time) {
hasGreater = true;
}
}
return hasGreater;
}I think I will wrap up this blog post for now, and continue writing the broadcast delivery middleware in part 2. Stay tuned!
Comments